Basic building blocks of KNIME for data analytics
May 26, 2021
Retail sector got enhanced using KNIME
May 27, 2021
KNIME Analytics Platform: Machine Learning Made Easy

The new era of Low Code No Code (LCNC)!
Introduction
Data Science is abounding. It considers different realms of the data world including its preparation, cleaning, modeling, predicting, and much more. If you are new to Knime, kindly read the blog “Beginner’s guide for KNIME: What, Why, How” and also understand “Basic building blocks of KNIME for data analytics”. By end of this article, you will learn to predict Airbnb Rental Prices in New York City, without writing a piece of code! You can download the dataset and its description from here. (~ 49k rows x 16 Features). Also, you can import various Workflows, Datasets, Nodes, Components, and much more from KNIME Hub.
Objective:
From the past historical data, we are predicting the Prices for NYC(New York City) Airbnb Rental, this dataset contains 16 different attributes in this Price is our target variable,so we are selecting appropriate feature to build our regression model to predict the price of rooms and at the end, we are trying to predict price on our test or unseen data using our model.

1. Importing the data files
Let us start with the first yet very important step in understanding the problem; importing our data.
Drag and drop the “File Reader Node” to the workflow and double click on it. Next, browse the file you need to import into your workflow.
In this article, as we will Predicting Prices of NYC Airbnb Rental, hence we will import the dataset of NYC Airbnb Rental.
2. How do you clean your Data?
GIGO (Garbage in Garbage Out) is generally true for any Data Science projects. Results are as good as data.
Before training your model, we need to perform Data Cleaning and Feature Extraction. You can impute missing values using “Missing value Node” but KNIME also provides the facility of Interactive Data Cleaning.
2.1 Finding Missing Values & Imputations
Before we impute values, we need to know which ones are missing.
Go to the node repository again, and find the node “Missing Values”. Drag and drop it, and connect the output of our File Reader to the node.
Now when we execute it, our complete dataset with imputed values is ready in the output port of the node “Missing Value”. 2.2
Interactive Data Cleaning
This KNIME component allows you to apply various data cleaning steps interactively. The default configuration will implement cleaning of missing values and outliers. You can directly drag and drop this component from the KNIME hub.
Available pre-processing steps:
(I) Automatic type guessing: determine the most specific type in each string column and change the column types accordingly.
(II) Treatment of missing values: separate configurations for missing values in string and number columns.
(III) Outlier removal: configuration on how to treat outliers.
After importing this KNIME component your workflow executes it and right-click on it and open an interactive view.
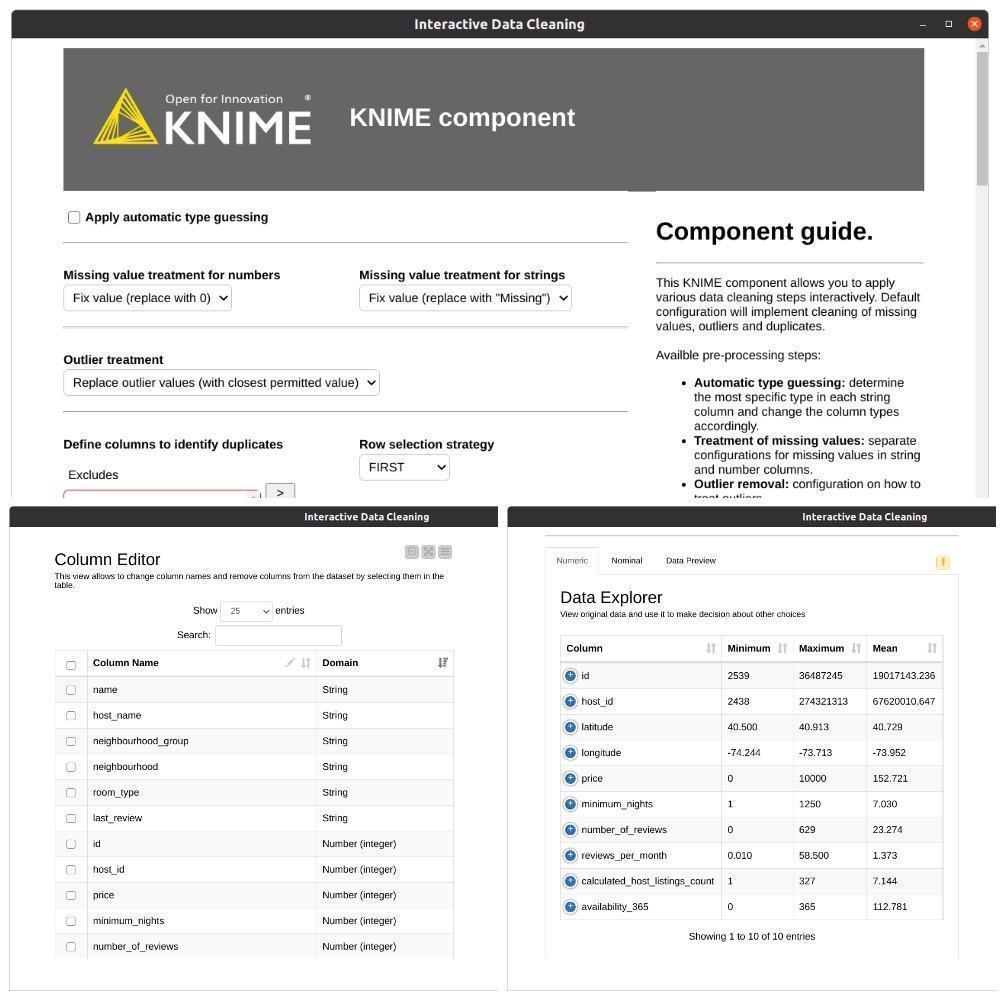
Interactive View
Using this Interactive data cleaning you can perform different kinds of tasks like Remove or Impute Missing values, changing Column name, Remove columns from the dataset, and also you can do Data exploration in interactive mode.
3. Machine Learning modeling in KNIME
Let us take a look at how we would build a machine learning model in KNIME. After data cleaning, pre-processing and feature engineering we know that for modeling, first we partition our data. Go to Node repository and import “Partitioning Node”.
3.1 Partitioning
In the configure of Partitioning Node, we have to specify the size of the first partition, click OK and execute the Node. You can choose from a variety of Partitioning techniques.
3.2 Implementing a Random Forest Model
Random Forest is a decision tree-based machine learning algorithm that leverages the power of multiple decision trees to arrive at decisions.
Random forest algorithms can be used for both classifications and regression problems. It provides higher accuracy through cross-validation. A random forest classifier will handle the missing values and maintain the accuracy of a large proportion of data.
For our problem, Let’s Go to the Node repository again, and find the “Random Forest Learner Node” and “Random Forest Predictor Node”. Drag and drop it, and connect the output of our Partitioning Node as below.
In Random forest learner configuration, we have to specify our target column as Price, click OK and execute the Node.
In Random Forest Predictor configuration, you can change the Prediction column name, press OK and execute the Node to see the Prediction, right-click on the Node, and select prediction output.
3.3 Model Evaluation
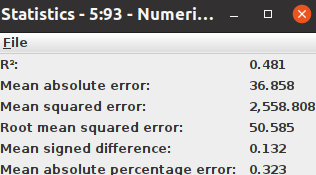
Go to the Node repository and drag and drop “Numeric Scorer Node” and Also you can use different techniques for model evaluation you can find different Node in the Node repository.
By right-clicking on Numeric Scorer and selecting Statistics you can find the values of R² and errors. This is the final workflow diagram that was obtained.

Observations
In this exercise, we only did the analysis using a random forest algorithm. In theory, we would use different models and feature engineering techniques to derive the most optional approach. Here, our objective is just to cover how KNIME can be used to solve a typical ML problem.
Using the R² measure we can validate our model, For example, an r-squared of 60% reveals that 60% of the data fit the regression model. Generally, a higher r-squared indicates a better fit for the model.
Conclusion
KNIME is a platform that can be used for almost any kind of analysis. In this article, we explored how to import a dataset, Data cleaning, and extract important features from it. Predictive modeling was undertaken as well, using a Random forest predictor to estimate Price and get the values of R² and error.
Hope this tutorial has helped you uncover aspects of the KNIME Analytics Platform that you might have overlooked before. Will be posting more articles on KNIME and Data Science in the future.
Just try this out, and you can contact us on Linkedin or info@cilans.net for any queries.
Happy KNIMING !!
Author: Team Cilans